Im Hintergrund speichert Home Assistant Daten, Zustände und die Verläufe deiner Entitäten in Datenbanken. Standardmäßig kommt dafür SQLite zum Einsatz. Falls du schon länger Home Assistant nutzt, hast du vielleicht irgendwann auf eine extern gehostete Datenbank wie MariaDB umgestellt. Wenn du an der Datenbank deines Home Assistants nichts verändert hast, verwendest du sehr wahrscheinlich SQLite. Auf diese Daten kann man direkt zugreifen, wenn man ein wenig SQL beherrscht. Um manuell über die Befehlszeile mit der SQLite-Datenbank zu arbeiten, benötigst du eine Installation von sqlite3 (Installationsanleitung). Alternativ kannst du den DB Browser for SQLite nutzen. Damit erhältst du einen praktischen Viewer…
Hallo Olli, ich denke im SQL Code für SQLite ist ein Copy/Past Fehler ![]() … FROM
… FROM statistics… … weitere ...Viele Grüße Gunter
Jetzt hat die Formularfunktion den Text „...“ entcodet ![]()
Hi Gunter, du hast vollkommen Recht - sorry für den Fehler! Ich habe es im Beitrag korrigiert! Vielen Dank für deinen Hinweis!
Viele Grüße
Olli
Hallo Olli
Über Grafana werden über eine InfluxDB für einen Sensor Werte angezeigt, die nicht sein können, da ich die Daten über ein input_select fülle.
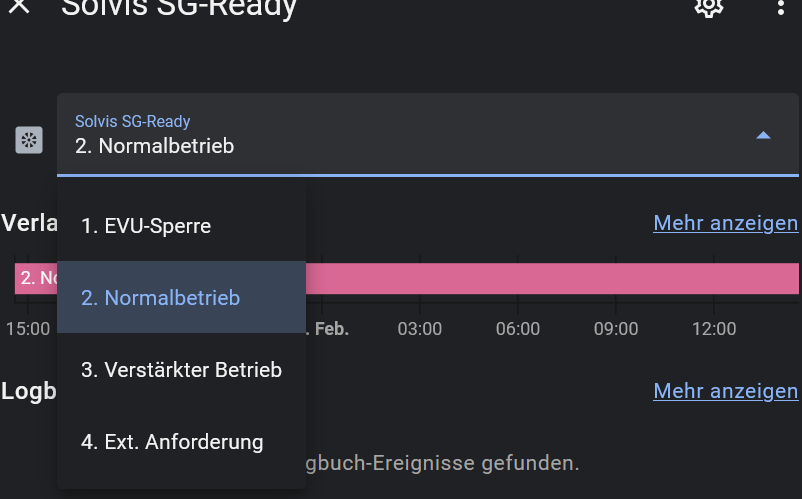
Gefüllt wird dieser input_select über eine Automatisierung (theoretisch auch manuell) und dann in einen Sensor übernommen und in zweiten Sensor nur die 1. Stelle.
- name: Tibber Status Solvis SG-Ready
state: >-
{{states('input_select.solvis_sg_ready') }}
unique_id: tibber_status_solvis_sg_ready
- name: Tibber Status Solvis SG-Ready num
state: >-
{{states('input_select.solvis_sg_ready')|truncate(1, true, '') }}
unique_id: tibber_status_solvis_sg_ready_num
Bei bestimmten Schaltvorgängen sehe ich in Grafana an stelle des von 4 auf 2 geschalteten Wertes aber 3 (einmal sogar 3,5 ???)
Die Anzeige der Sensoren in HA zeigen doch immer 2 an.
Um dieses Verhalten aufzuspüren wollte ich direkt in die DB schauen und habe deinen Beitrag gefunden. Doch meine Anpassung deines Beispiels erzeugt kein Ergebnis
SELECT ROUND((SELECT state FROM statistics INNER JOIN statistics_meta ON statistics.metadata_id=statistics_meta.id WHERE statistics_meta.statistic_id='sensor.tibber_status_solvis_sg_ready_num' AND created_ts < strftime('%s','2025-02-04 14:00:00') ORDER BY created_ts DESC LIMIT 0,1) - (SELECT state FROM statistics INNER JOIN statistics_meta ON statistics.metadata_id=statistics_meta.id WHERE statistics_meta.statistic_id='sensor.tibber_status_solvis_sg_ready_num' AND created_ts > strftime('%s','2025-02-04 11:00:00') ORDER BY created_ts ASC LIMIT 0,1),2) AS wert
(leider klappt das hier nicht mit Zeilenumbrüchen)
Siehst du evtl den Fehler in meinem Select?
Danke
@jove02 Hi! Aus der Ferne auf jeden Fall nicht ganz so easy, ich bin mir nicht sicher, ob ich es richtig verstanden habe. Aber hast du mal ein wenig mit den Zeiten gespielt? Je nach Setup ist ein Offset nicht ungewöhnlich (i. d. R. 1-2 Stunden bspw.).
Hallo Olli
vielen Dank für die schnelle Antwort.
Leider total verstanden.
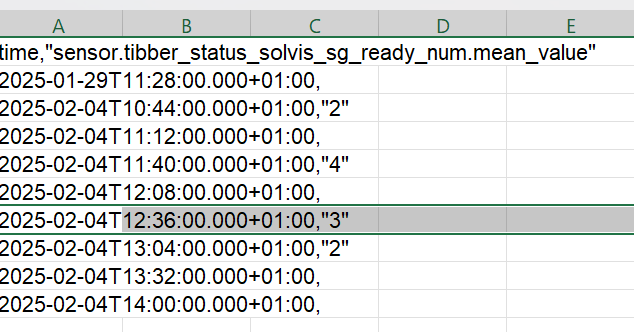
Auszug aus InluxDB. Grau der Eintrag mit 3, der eigentlich nicht vorkommen kann
Input_select und Sensoren auf HA
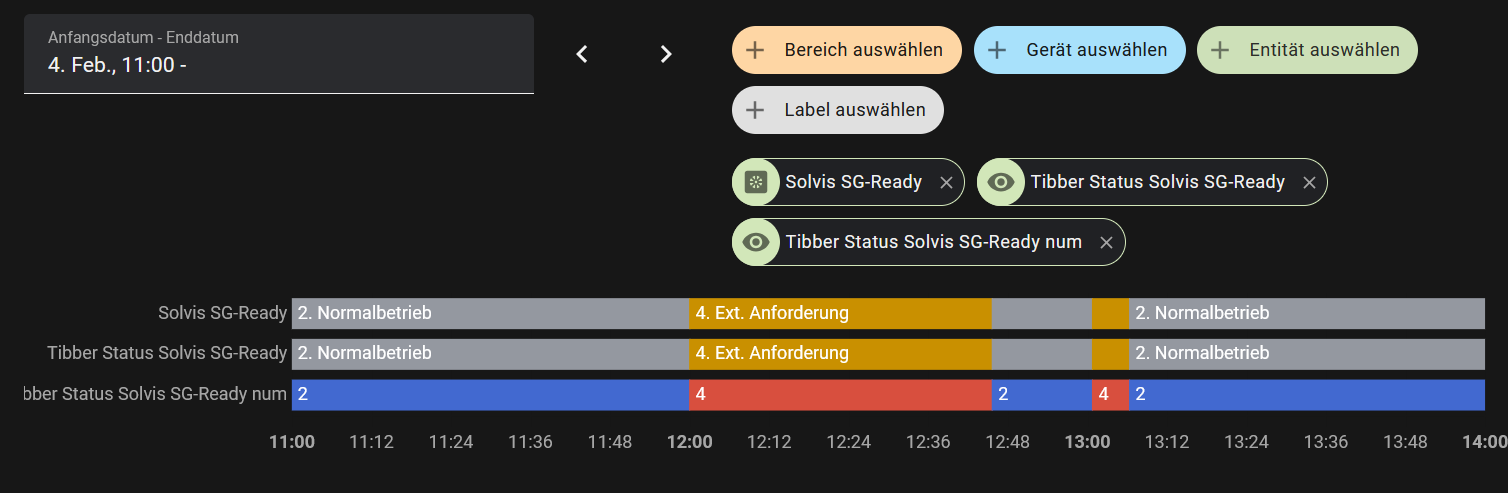
Man sieht zur InfluxDB die Abweichung, die ich versuche zu ergründen. Dazu wollte ich mit SQL auf die HA-DB zugreifen, denn es muss in HA den Wert 3 geben, wo sollte er sonst herkommen, und das nicht nur einmal.
Daher meine bitte, kannst du einmal den obigen SELECT prüfen.
Danke
@jove02 Danke für die weiteren Details!
Was ich in dem Video und Blogbeitrag beschreibe, ist wie man eine Wertentwicklung einer Entität durch das „vergleichen“ zweier Werte generiert (also Wert a (neu) abzüglich Wert b (alt) ergibt die Wertentwicklung).
Was du benötigst ist vollkommen anders gelagert und du wirst das anhand meines Beispiels nur mit unnötig viel Aufwand hinbekommen (also möglich ist es sicherlich, aber alles andere als pragmatisch).
An deiner Stelle würde ich mir direkten Zugriff auf die DB verschaffen um dort direkt (also ohne den Umweg über HA) Selects absetzen zu können. Das beschreibe ich in dem Video auch (https://youtu.be/qe8Syxfo-LY?si=5XVF19W1qKPfglIC&t=886). Wenn du direkten Zugriff auf die DB hast, kann ich dir gerne mit dem Select behilflich sein.
Ich hatte wohl die Integration SQL installiert und nicht das Addon. Aber auch damit stoße ich an meine Grenzen, denn die relationale DB ist ohne strukturkenntnisse mal nicht eben pre Klick abzufragen. Wie ich das sehe, muss der Select über mehrere Tabellen gehen.
Daher nehme ich gerne dein Angebot tur Unterstützung beim Select an.
@jove02 Probier mal folgenden Select aus:
SELECT state FROM statistics INNER JOIN statistics_meta ON statistics.metadata_id=statistics_meta.id WHERE statistics_meta.statistic_id='sensor.tibber_status_solvis_sg_ready_num' AND created_ts > strftime('%s','2025-02-04 12:09:00') AND created_ts < strftime('%s','2025-02-04 13:00:00') ORDER BY created_ts DESC
Durch die Angaben „created_ts > …“ und „created_ts < …“ sollte die Ergebnisliste deinem XLS-Screenshot von weiter ohne entsprechen bzw. den auffälligen Eintrag mit „3“ beinhalten.
Wenn du in der DB arbeitest, beachte, dass du keine Inserts, Updates oder Dinge in die Richtung machst, da du damit dein HA „beschädigen“ kannst. SELECT-Abfragen stellen hingegen kein Problem dar!
Im Add On habe ich auf Basis deiner Beispiele ein erstes Query gebastelt. Dabei ist mir aufgefallen, dass für den Template-Sensor keine Statistik in der DB war. Ursache ein fehlendes „state_class: measurement“.
Jetzt kann ich natürlich darüber rätseln, ob das die Ursache für den falschen Wert in der InflzxDB ist.
Voreinmal vielen Dank für deine Unterstützung.
Hallo Olli
jetzt benötige ich bitte doch nochmals deine Unterstützen beim Anzeigen „ts“ im gängigen Format
SELECT mean, datetime(created_ts) FROM statistics INNER JOIN statistics_meta
ON statistics.metadata_id=statistics_meta.id
WHERE statistics_meta.statistic_id='sensor.tibber_status_solvis_sg_ready_num' AND
created_ts > strftime('%s','2025-02-04 00:00:00') ORDER BY created_ts

Versuche mal folgenden Code um created_ts zu transformieren:
SELECT mean, DATETIME(created_ts, 'auto') FROM statistics INNER JOIN statistics_meta
ON statistics.metadata_id=statistics_meta.id
WHERE statistics_meta.statistic_id='sensor.tibber_status_solvis_sg_ready_num' AND
created_ts > strftime('%s','2025-02-04 00:00:00') ORDER BY created_ts
Hallo Olli
vielen Dank, das war es
Jürgen
Hallo Olli,
ich habe zwei Anwendungsfälle, die ich separat poste.
Anwendungsfall 1: Ich lese meinen Stromzähler mit einen IR Kopf und Tibber aus. Beide Zählerstände landen in HA. Aus mir nicht erklärlichen Gründen, waren für die Einspeisewerte vom Zähler nur die letzten 3 oder 4 Monate in HA. Die Tibber Werte waren aber durchgängig vorhanden.
Hast Du eine Idee, wie man das versehentlich hinbekommt? Im SQLite Web habe ich bewusst nur Select Statements ausgeführt, aber viel in den Developertools HA unter die Haube geschaut.
Die Werte vom Tibber (Medadata_id 179) habe ich über INSERT INTO auf den Zähler (Metadata_id 168) übertragen. Da noch Werte vorhanden waren, nur die vor dem ersten start_ts Eintrag für ID 168
INSERT INTO statistics (created,start, mean, min, max, last_reset, state, sum, metadata_id, created_ts, start_ts, last_reset_ts)
SELECT
created,
start,
mean,
min,
max,
last_reset,
state,
sum,
168 AS metadata_id,
created_ts,
start_ts,
last_reset_ts
FROM statistics
WHERE metadata_id = 179 AND start_ts < 1765400000.0 AND true
Grüße
Markus
Hallo Olli,
hier mein zweiter Fall, und ich knacke noch an der Nuss, bei dem Du mir vielleicht helfen kannst.
Mein Stromzähler hat sich über einen Zeitraum von 3 Monaten verschluckt und die Werte um 6 stellen nach Links verschoben. Die richigen Werte liefert mir Tibber.
Mit einem reinen Insert ist es nun nicht mehr getan, weil ja Werte vorhanden sind, die aktualisiert werden müssen.
Hier die fehlerhaften Werte aus „statistics“ für Sensor 167
state sum metadata_id start_ts
4807.297 5650.215391840034 167 1714208400.0
0.048 5650.263391840033 167 1714212000.0
0.048 5650.263391840033 167 1714215600.0
0.048 5650.263391840033 167 1714219200.0
0.048 5650.263391840033 167 1714222800.0
Hier die richtigen Werte aus „statistics“ für Sensor 178
state sum metadata_id start_ts
4807.297 1531.3169 178 1714208400.0
4807.317 1531.337 178 1714212000.0
4807.317 1531.337 178 1714215600.0
4807.374 1531.3939 178 1714219200.0
4807.418 1531.4379 178 1714222800.0
Die Abfrage müsste über eine virtuelle Zwischentabelle funktionieren, bei der die o.g. Tabellen erzeugt werden und dann die Werte mit dem 178 Wert aktualisiert, der den gleichen start_ts Wert hat. Das bekomme ich bisher leider nicht hin.
Update 167.state WHERE 167.start_ts=178.start_ts ist.
Wie berechne ich zudem aus den state-werten die richtige Summe in Spalte „sum“? Das Energy Dashboard hat bisher am Anfang und Ende meiner SQL Korrketuren einen Peak. Diese habe ich manuell in der Statistik korrigiert. Die richtigen Werte für die jeweilige Stunde habe ich ja im Sensor mit den richtigen Daten.
Danke und Grüße
Markus
@markus Verstehe ich dich richtig, dass deine eigentliche Frage ist, warum die Daten für einen Zeitraum weg sein können?
Und wenn ich es weiter richtig verstanden habe, hast du es durch den INSERT geheilt?
Hi @markus
eine Verständnisfrage vorweg: Wieso ist der Summenwert von 178 kleiner, als die Einzel-States jeweils? Also ist da nicht ggf. noch mehr „schief“?
Für 167 willst du State jeweils mit dem gem. start_ts passenden State von 178 überschreiben/korrigieren? Und sum von 167 soll dann dynamisch berechnet werden?
Sorry für die Rückfragen, aber ich durchblicke deinen Plan noch nicht so genau…
VG
Olli
@olli Keine Ahnung, wie sich der Summenwert bildet. Ich vermute dass die Summe zum Zeitpunkt t0 = Inbetriebnahme auf Null steht. Der Zähler aber schon bei ~3500 stand.
Korrekt. Zum Zeitpunkt x soll der 178er wert in den 167er Wert geschrieben werden.
Ich habe keine Ahnung wie sum sich berechnet und welchen Effekt sie auf das Energy-Dashboard hat. Das wäre erstmal sekundär. Vermutlich gibt es ein paar Ausreißer beim Übergang. Aber das schauen wir dann.
Hier der Screenshot meines HA: das gelbe muss ins blaue ![]()
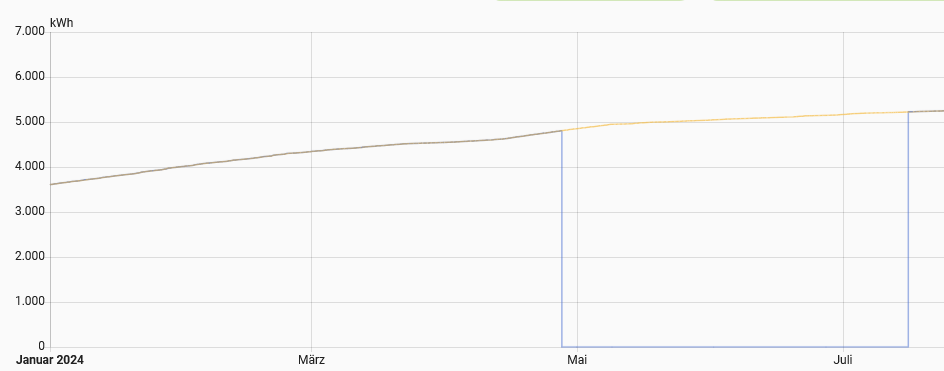
Danke und Grüße
Markus
Ich hab grad geschaut: die Summe bildet sich ab dem Zeitpunkt der Inbetriebnahme des Sensors. Der IR-Leser läuft schon länger als der Tibber Pulse.
Die Neuberechnung macht das vermutlich komplizierter, weil man nun die Differenz der aktuellen mit der vorhergehenden Zeile bilden muss.
Ich vermute im HA wird vor dem speichern der letzte gespeicherte Wert ausgelesen, dann minus jetzt() berechnet und als sum mit dem neuen Wert weggeschrieben.